- Bin-Case-Funktion in Oracle BI - 29. März 2021
- Persistant Staging Area - 24. März 2021
In diesem Beitrag möchte ich die Persistant Staging Area – kurz PSA – vorstellen, welche Roelant Vos in seinem Blog beschreibt. Diese ist in von uns betreuten Projekten erfolgreich im Einsatz.
DWH Basis
Ein Data Warehouse (DWH) ist oftmals in drei Grund bzw. vier Grundschichten unterteilt. Die Staging Area ist die erste Schicht und übernimmt die Daten 1:1 aus den Quellsystemen. In der optionalen Cleansing Area werden Daten gefiltert, bereinigt und kontrolliert bevor sie in die dritte Schicht den Core übertragen werden. Der Core ist innerhalb eines DWHs für die Integration und Historisierung der Daten zuständig. In der vierten Schicht, den Data Marts, werden meist Teilbereiche der Daten für bestimmte Anwendergruppen, z.B. Vertrieb, Logistik, etc. zur Verfügung gestellt.
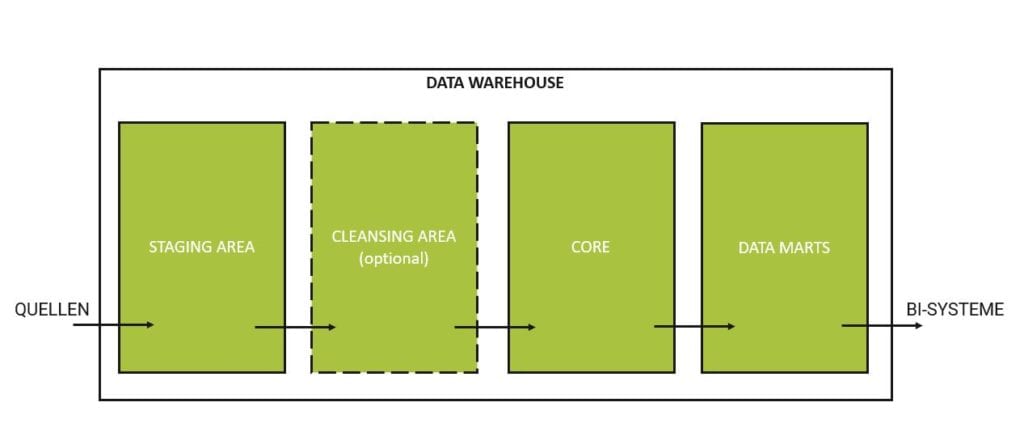
Abbildung 1: Data Warehouse Basisarchitektur
Stage und PSA
Die Staging-Schicht kann wiederrum in einer „Landing Area“ (originäre Staging Area, kurz: Stage) und eine „Persistant Area“ unterteilt werden.
Dabei übernimmt die Landing Area die ursprüngliche Aufgabe der Stage, die Schnittstelle zu den Quellsystemen zu bilden und die Datenextraktion daraus via Delta-Load aufzunehmen.
Die Persistant Staging Area hingegen speichert die Rohdaten aus dem Quellsystem langfristig und erhält Daten ausschließlich über die ihr vorgelagerte Landing Area. An der Tabellenstruktur der PSA ändert sich hierbei gegenüber der Landing Area nichts.
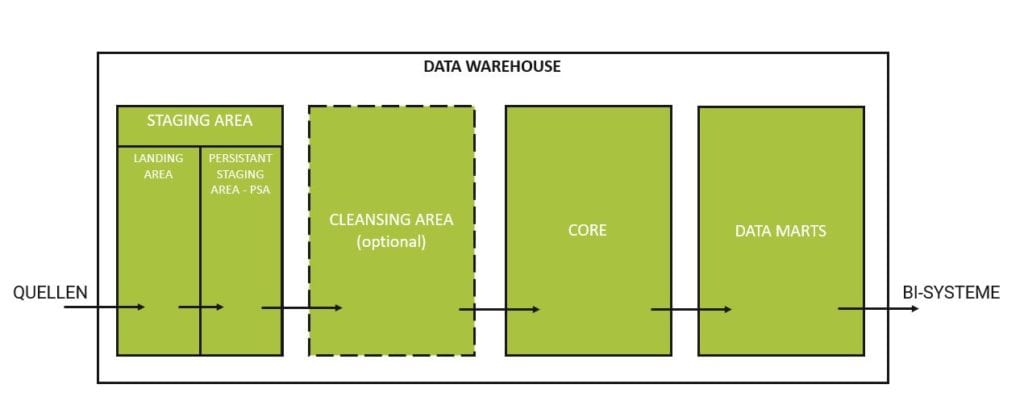
Abbildung 2: Data Warehouse Basisarchitektur mit Aufteilung der Stage in Landing Area und PSA
Warum eine PSA?
Mit der Historisierung der Rohdaten aus dem Quellsystem entsteht so ein einfach handhabbares Archiv der Quelltabellen. Daraus kann, im Fall der Fälle, der komplette Core neu erstellt bzw. neu geladen werden, ohne dabei auf die Quellsysteme zurückgreifen zu müssen. Auch die Historisierung im Core kann durch die PSA so wieder 1:1 hergestellt werden.
Weiter ermöglicht die PSA den DWH-Entwicklern und -Administratoren die Historie von einzelnen Datensätzen genau nachzuverfolgen. Die Verarbeitung der Sätze von PSA Richtung Core kann schneller nachvollzogen werden. In der Zusammenarbeit mit dem Kunden hat sich diese Möglichkeit oftmals als sehr hilfreich erwiesen.
Zuletzt kann die PSA auch als Operational Data Store (ODS) für Data Analytics-Methoden dienen.
In Kauf genommen werden müssen hingegen weitere ETL-Strecken und ein erhöhtes Speichervolumen für das DWH.
Implementierung
Die Tabellenstruktur der PSA, der Stage und des Quellsystems sind, bis auf zu ergänzende Attribute im DWH, identisch. Die Quelldaten sind somit 1:1 in der PSA verfügbar. Fremdschlüsselbeziehungen sind, wie üblich, in der gesamten Stage-Schicht entfernt.
Historisiert wird nach dem Verfahren „Slowly Changing Dimension Type 2“ (SCD2). Damit das möglich ist, müssen je PSA-Tabelle folgende Attribute ergänzt werden:
- Primärschlüssel – bestehend aus ID und Ladedatum
- Eindeutige ETL-Prozess-ID – z.B. DWH_Lade_ID, für den Abgleich zwischen Stage und PSA
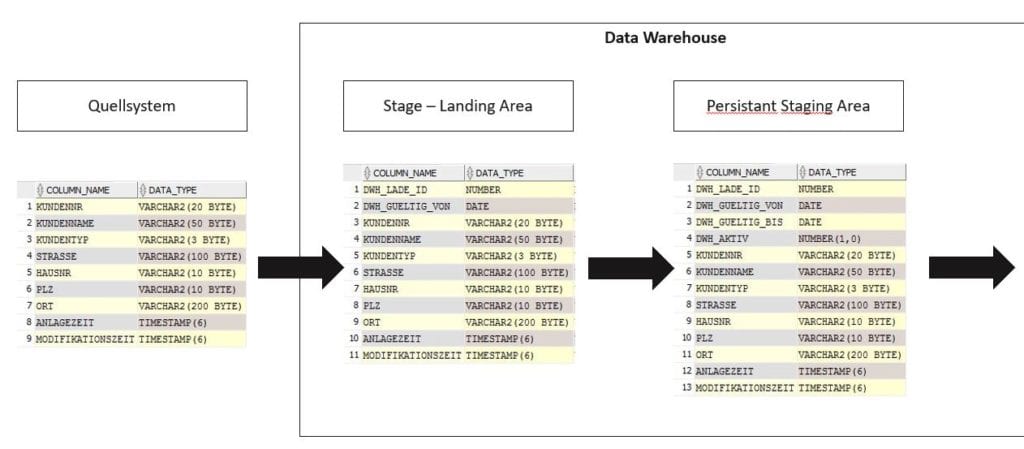
Abbildung 3: Tabellenstruktur von Quelle, Stage und PSA: Beispiel Tabelle „Kunde“
In diesem Beispiel sind in der Stage die Felder DWH_LADE_ID und DWH_GUELTIG_VON hinzugekommen. In der PSA sind neben den zusätzlichen Attributen der Stage noch DWH_GUELTIG_BIS und DWH_AKTIV eingefügt. Diese sind zwar nicht zwingend notwendig für einen SCD2-ETL-Load, aber nützlich zu Verständlichkeit und Auswertbarkeit durch die Entwickler.
Der Delta Load findet von Quelle zu Stage statt mithilfe der Felder ANALAGEZEIT und MODIFIKATIONSZEIT statt.
Von Stage zu PSA via SCD2 Delta Load, anhand DWH_GUELTIG_VON und KUNDENNR aus der Stage-Tabelle. Dabei werden folgende Fälle unterschieden:
- Neuer Datensatz –> einfügen
- Vorhandener Datensatz und Änderungen –> einfügen und alten Satz „schließen“
- Vorhandener Datensatz, keine Änderungen –> nichts unternehmen
Vorteil: Automatisierung
Die einfache Struktur ermöglicht die automatische Generierung der Landing- und PSA-Tabellen anhand der Metadaten aus den Quellen. Ebenso kann der ETL-Prozess von Quelle bis zur PSA vollständig automatisiert generiert werden. Was den Nachteil weiterer ETL-Strecken ausgleicht.





