
- What are you? null, undefined – or just nullish? - 22. Oktober 2021
- AI-based Code Autocompletion with TabNine - 13. Juli 2021
- Building a Home Office Challenges App with Kafka, Kubernetes and StencilJS – Part 2: Introduction to Apache Kafka - 18. Januar 2021
This is the second in a series of articles on our “Home Office Challenges App (HOCA)”. It offers an introduction to Apache Kafka. The next article will go into more detail and describe some of the challenges we faced.
Apache Kafka is a distributed event streaming platform. Simply speaking, it allows applications to transmit and receive data in real-time. Because Kafka uses a distributed architecture, it ensures a high level of fault tolerance and scalability. It is especially suited for working with large amounts of data.
Events
In real life, an event is something which happens. In Kafka, an Event is the record of something which happens. Events can come in all kinds of different forms. For example, an Event can be the record of a business transaction or an entry in an application’s error log. The possibilities are near endless. Still, all Events must share these three basic attributes:
- Key: A unique identifier
- Value: The Event’s content, which can be almost anything
- Timestamp: The point in time when the event happened
Applications which publish new events to Kafka are called Producers. Other applications, which are called Consumers, can subscribe themselves to Kafka so that they receive new events as soon as they are created. Producers and Consumers are fully independent of each other.
Topics and Partitions
If we want to handle large numbers of events in a meaningful way, we need to find ways to organize and store them. For this, Kafka uses Topics. Whenever a producer creates a new Event, it assigns the event to a specific Topic. The Consumers who are interested in a particular Topic can subscribe to it so that they receive every event which belongs to it.
But what if multiple Consumers want to read from a Topic at the same time? If we split the Topic over multiple machines, the Consumers can access each of these Partitions in parallel. While it is possible to have only one Partition per Topic, it is advisable to choose a higher number.
Brokers and Zookeepers
The servers which Kafka uses are called Brokers. Each one of them can handle hundreds of thousands of Events per second. Brokers are always part of a cluster. Some clusters only have one broker, but it is recommended to use multiple Brokers to improve load balancing and reliability.
Management and coordination of the Brokers in a cluster is performed by the Zookeeper. When a Broker fails, or a new one is added, Zookeeper informs the Consumers and Producers about it. In this way, it is ensured that the Kafka cluster continues to operate reliably.
The following diagram gives an overview of the interactions of the most important components of Kafka’s architecture:
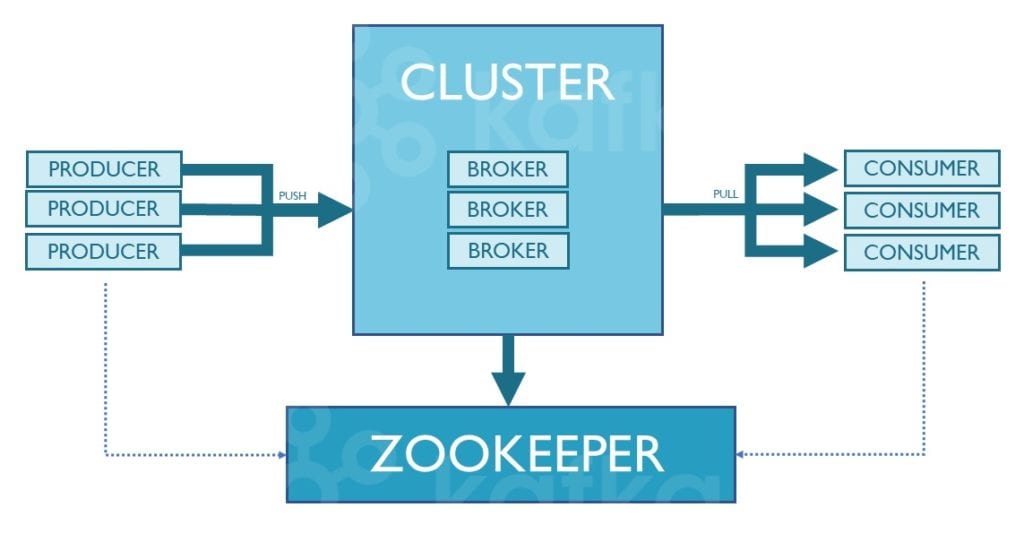
In the next article, we will discuss several more advanced features of Apache Kafka, and describe various issues we encountered with Kafka during the development of our “Home Office Challenges App”.
Stay tuned!





